The TensforFlow Ruby bindings have achieved a milestone – its now possible to train a model to solve linear regression. I know, that doesn’t sound like much, but in fact its more than other Ruby TensorFlow bindings have achieved and in fact its more than most other TensorFlow language bindings have achieved.
Before continuing, note this is using TensorFlow in graph mode, i.e., the default mode before TensorFlow 2.0. Although the Ruby bindings do support eager execution, they do not yet support training with eager execution. That’s a todo for the future (one thing at a time!).
So why did it take a three weeks of part-time programming to solve such a simple problem? First, because there is a decently steep learning curve to understanding how TensorFlow is put together – it is 1.7 million lines of code after all. And second, it requires implementing a lot of support infrastructure. In particular:
- Support a number of TensorFlow operations
- Creation of TensforFlow computation graphs
- Graph execution
- Implementation of autodiff to calculate gradients used for back-propagation
- Implementation of an optimization algorithm such as gradient descent
To get there required:
─────────────────────────────────────────────────────────────────────────────── Language Files Lines Blanks Comments Code Complexity ─────────────────────────────────────────────────────────────────────────────── Ruby 184 16772 2913 807 13052 120 Markdown 2 100 26 0 74 0 Plain Text 2 22 4 0 18 0 Shell 2 25 3 1 21 1 Gemfile 1 4 1 1 2 0 Rakefile 1 96 9 20 67 5 gitignore 1 10 0 0 10 0 ─────────────────────────────────────────────────────────────────────────────── Total 193 17029 2956 829 13244 126
Most of the required functionality, except the optimization algorithm, is provided by the C API, but requires work to hook up.
Autodiff
The most interesting part was implementing autodiff, also known as reverse-mode differentiation. There are plenty of resources on the web if you want to dive-in, but I few that I found particularly helpful were:
- Backprop and Automatic Differentiation (University of Washington, pdf)
- Calculus on Computational Graphs: Backpropagation (Christopher Olah)
- Hands-On Machine Learning with Scikit-Learn and TensorFlow (sorry you need to have a subscription to see the full content)
Autodiff makes it possible to train your model. Your model will start off giving you incorrect answers and you want to teach it how to give you correct answers. To do that requires calculating how changes in the result should change various model parameters. And that is done by calculating the gradient at each computation step.
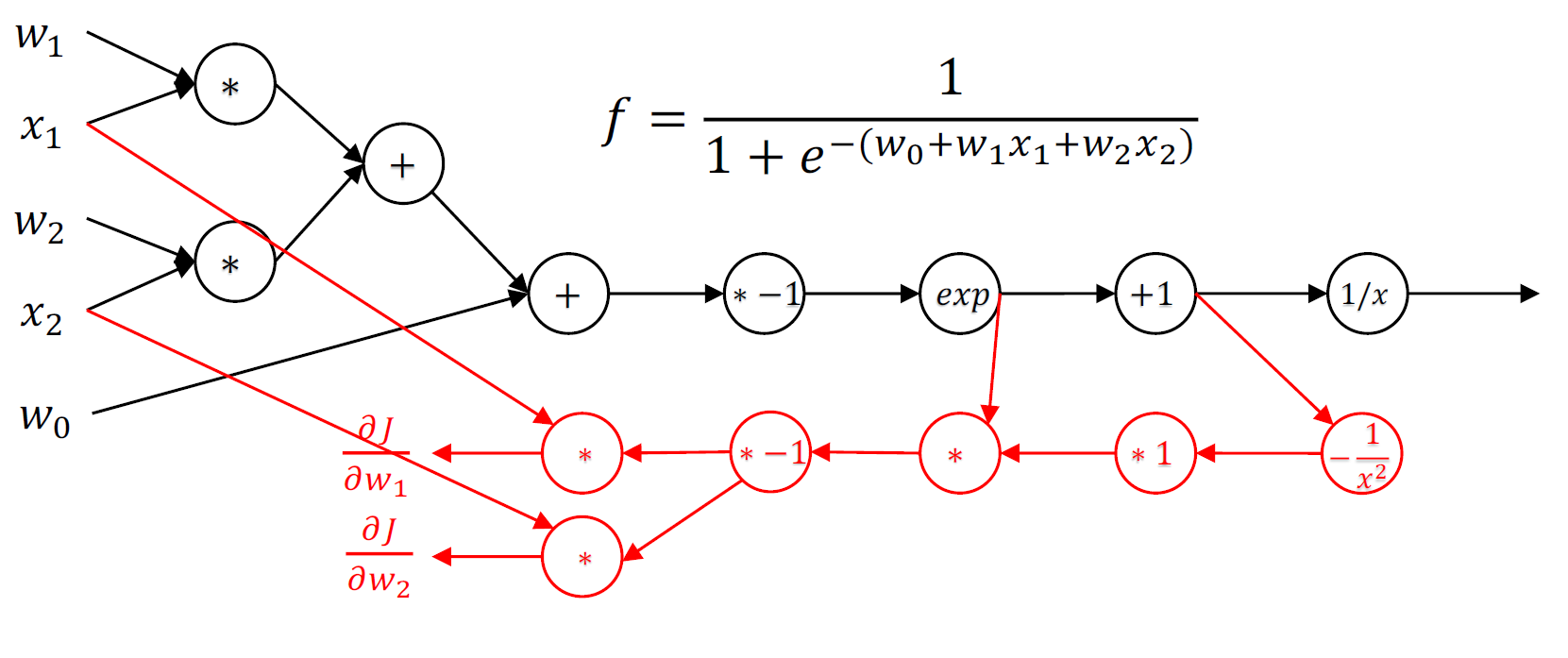
To perform autodiff with TensorFlow, you start at the result node and you work your way back to the inputs. At each step, you insert a parallel set of nodes into the computation graph for each node you want to evaluate. Hopefully this picture from the University of Washington makes it clear:

The black nodes are the calculations you want to perform and the red nodes are inserted to calculate the gradients. Autodiff is implemented in gradients.rb (or gradients.py is you are using Python), and in particular the derivative method. Its quite elegant code – a nice short recursive method.
Let’s walk through how this works. To start, loop through each input of interest (the variables we want to train):
def gradients(output, inputs, grad_ys: nil, name: "gradients", stop_operations: Set.new)
self.graph.name_scope(name) do
inputs.map.with_index do |input, i|
operations_path = self.path(output, input)
next if operations_path.empty?
self.derivative(nil, output, stop_operations, operations_path)
end.flatten.compact
end
endFor each input, determine the path through the graph that needs to be traversed to get to the output. For now I did this the brute force way by first tracing from the result node back through the graph and then tracing forward from the input of interest (say in the graph above you want to calculate how x1 varies with the result). Then path is the intersection of the two traces.
def path(output, input)
forwards = self.graph.forward(input)
backwards = self.graph.backward(output)
forwards.intersection(backwards)
endOnce you know the path that needs to be traversed, then call the derivative method (below is a simplified version):
def derivative(gradient, operation, stop_operations, operations_path)
inputs = operation.inputs.select do |input|
input_operation = input.operation(self.graph)
operations_path.include?(input_operation) && !stop_operations.include?(input_operation)
end
return gradient if inputs.empty?
outputs = operation.outputs
# These are the outputs from the operation
y = FFI::Output.array_to_ptr(outputs)
# These are the inputs to the output operation
x = FFI::Output.array_to_ptr(inputs)
# This is the gradient we are backpropagating
dx = if gradient
FFI::Output.array_to_ptr(gradient.outputs)
end
# This is the gradient we want to calculate
dy = ::FFI::MemoryPointer.new(FFI::Output, inputs.length, true)
Status.check do |status|
FFI.TF_AddGradients(self.graph,
y, outputs.length,
x, inputs.length,
dx, status, dy)
end
# We are done with this operation, so backpropagate to the input operations
inputs.map.with_index do |input, i|
dy_output = FFI::Output.new(dy[i])
unless dy_output[:oper].null?
input_operation = Operation.new(self.graph, input[:oper])
dy_operation = Operation.new(self.graph, dy_output[:oper])
self.derivative(dy_operation, input_operation, stop_operations, operations_path)
end
end
endThe gradient is the value we are backpropagating (its start value would typically be the result of your loss calculation). The operation is the current calculation of interest – i.e., a TensorFlow node. We first check the operation’s inputs and verify they should be processed – are they on the operation path and not marked as stop operations?
Next, insert the appropriate autodiff nodes by calling the TensorFlow C API method TF_AddGradients. The api call takes the node’s inputs and outputs, the starting gradient and calculates the input gradient. Next, recursively call the derivative method for each input to the result node. Nice and easy.
Optimization – Gradient Descent
Once the graph has been augmented with the autodiff nodes, its possible to train your model. This can be done using various algorithms, but for now tensorflow-ruby implements Gradient Descent. In TensorFlow, this code is implemented in Python and thus needs to be ported to Ruby.
Its not hard to do, but luckily, Joseph Emmanuel Dayo has already done it as part of his amazing project TensorStream. Unlike tensorflow-ruby, which wants to provide bindings to TensorFlow, Joseph reimplemented TensorFlow entirely in Ruby. As part of that, he obviously had to port the various training algorithms to Ruby. Modifying his code to work with tensorflow-ruby was quick and easy.
And now tensorflow-ruby can solve linear regression problems!